ACGPN 모델 소개
사용한 모델은 ACGPN(Adaptively Content Generating and Preserving Network)으로, 2020년 SOTA(State-of-The-Art)를 달성한 모델입니다!
ACGPN의 inference 과정
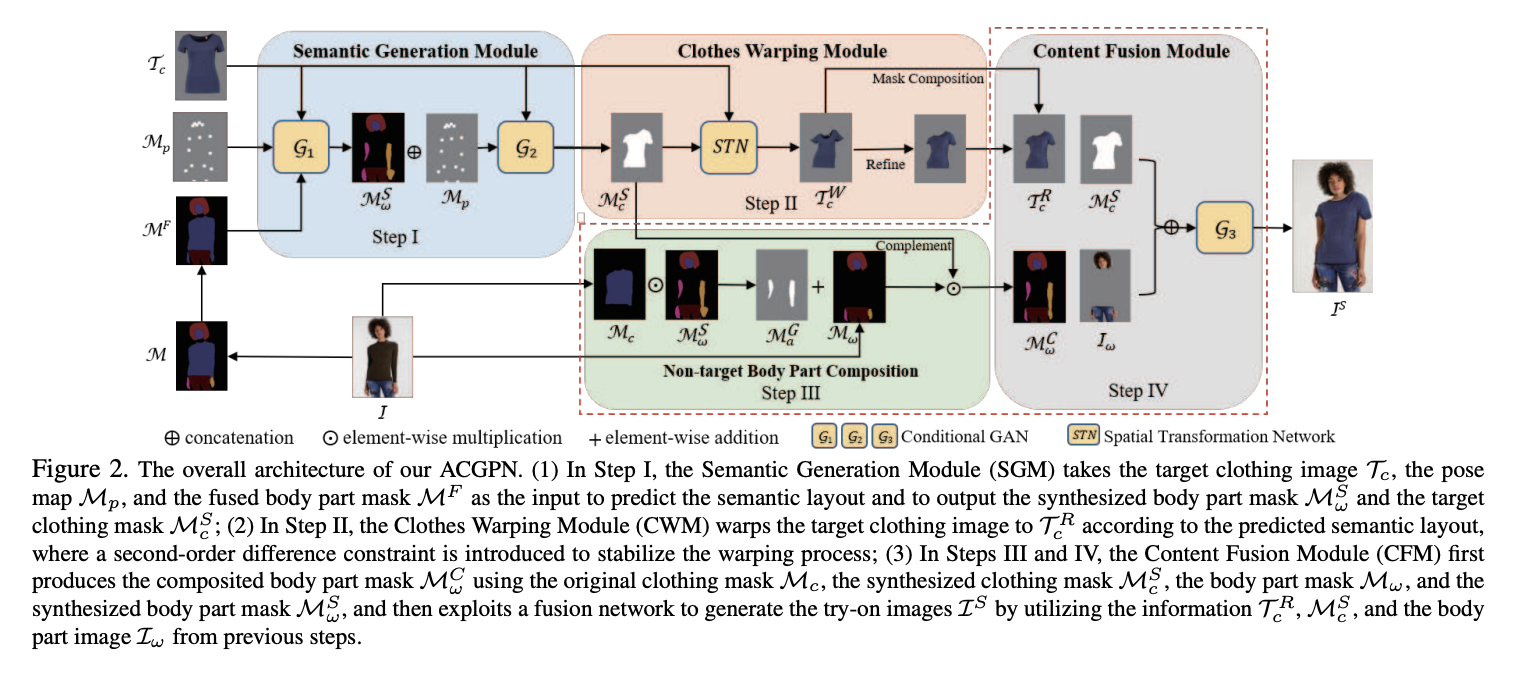
위 이미지는 논문에 기재되어 있는 ACGPN의 inference 과정입니다. ACGPN에서는 크게 3가지 주요 과정이 포함되어 있습니다.
첫번째는 주어진 이미지로부터 semantic layout을 생성하는 것입니다. 옷 이미지의 경우 이미지 내에서 옷이 차지하는 영역을 검출하고, 사람 이미지의 경우 각 부위 별로 영역을 검출합니다. 다음으로 자연스러움을 위해 옷을 warping 시키는 과정이 포함되어 있습니다. 이때 warping은 이전에 추출했던 옷의 semantic layout에 맞게 생성합니다. 마지막으로 앞서 생성했던 semantic layout, warped clothes, 입력으로 들어왔던 이미지들을 모두 통합하여 새로운 피팅 이미지를 생성해냅니다. 논문의 저자들은 이러한 세부적인 과정을 통해 이전 SOTA 모델과 비교했을 때, 더 정확한 퀄리티와 디테일적인 요소 면에서 앞서나갈 수 있다고 주장하였습니다.
마찬가지로 논문에 기재된 다음 이미지는 모델 학습 파이프라인을 보여주고 있습니다. 크게 3가지의 GAN 모델과 STN이라는 모델을 활용하고 있습니다.
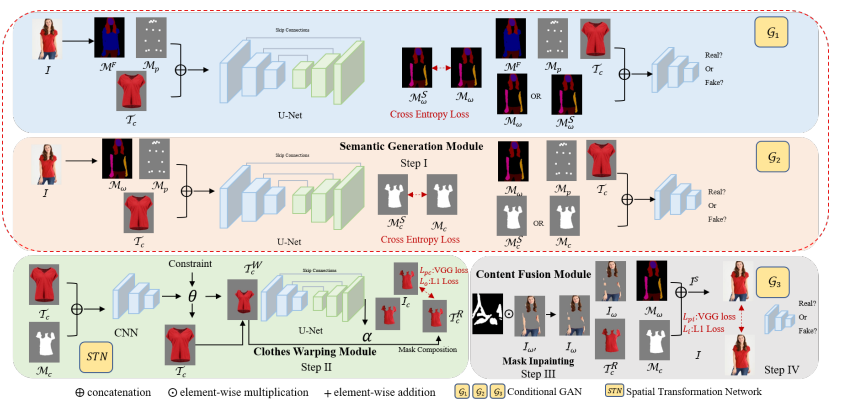
GAN
GAN 모델은 Generator와 Discriminator 두 모델이 서로 경쟁하며 학습하는 구조를 가지고 있습니다. Generator의 경우 fake 이미지를 생성하는 역할을 하며, Discriminator의 경우 Generator가 생성한 fake 이미지의 진위 여부를 판별합니다. 논문에서 활용된 GAN은 Conditional GAN으로, 기존 GAN에 특정한 조건을 부여하여 이미지를 생성하게 합니다. 예를 들어 신발 스케치 이미지가 주어진다면(조건), 이에 맞추어 채색된 신발 이미지를 생성하는 등의 task가 있습니다.
STN
STN은 옷을 자연스럽게 warping 해주는 역할을 수행하며, CNN과 U-Net을 활용하여 학습을 진행하게 됩니다.
결론
이렇듯 ACGPN은 세부적인 단계로 나누어져 있어 착붙 서비스에 활용하기 적합하다고 판단했습니다. 특히 다른 모델들에 비해 옷을 warping하여 자연스럽게 만들어주는 능력이 뛰어나 가상피팅의 디테일함을 살릴 수 있다고 생각했습니다.
현실적 제한 요소 및 그 해결 방안
human parsing 단계에서의 딜레이 발생
기존 가상피팅 서비스는 매 가상피팅 요청마다 사람 사진 촬영과 옷 선택을 수행하도록 계획되었습니다. 하지만 모델이 사람 이미지에서 pose estimation을 수행하고, 옷 이미지에서 segmentation하는 과정을 포함하여 옷을 생성하는 과정 자체가 가벼운 task는 아니기 때문에 실시간 어플리케이션 사용을 위해서는 시간이 오래 걸리는 문제가 있었습니다.
따라서, 매 가상피팅 시에 사람을 촬영하는것이 아니라, 회원가입 이후 첫 로그인 시에 사용자의 사진을 촬영하여 위 문제점을 해결하였습니다.
모델 재학습의 어려움
저희 어플리케이션은 이미 학습이 완료된 딥러닝 모델을 사용하여 가상 피팅 서비스를 제공합니다. 따라서 모델이 학습한 데이터와 상이한 input 이 들어올 경우, 예상과 다른 결과가 도출될 수 있습니다.
사용자 사진과 옷 이미지에 대한 가이드 라인 제공
1. 사용자 사진
저희는 사람의 자세와 배경에 따라 모델의 성능이 결정될 것이라고 가정했습니다. 실제로 목 아래부터 발목까지 나타난 사용자 사진을 모델의 input 으로 넣었을 경우, human parsing 이 제대로 이뤄지지 않는다는 것을 찾아냈으며, “사용자 사진” 데이터를 학습 데이터와 최대한 일치하도록 만드는 것이 중요한 요소라고 판단했습니다.
따라서, 사용자 사진을 촬영하는 단계에서 가이드라인을 제시하고 타이머 기능을 추가하여 사용자가 충분한 시간동안 적합한 자세로 촬영할 수 있는 환경을 구성했습니다.

2. 옷 이미지
옷 이미지의 경우 옷만 존재하는 이미지여야 함을 찾아내었습니다.
“무신사" 쇼핑 플랫폼의 데이터를 크롤링하여 자원을 구성하는 서비스 특성 상, 패션 모델이 옷을 착용하고있는 이미지가 수집될 가능성이 높습니다. 따라서, 크롤링 단계에서 사람이 입고있지 않은 옷의 이미지를 classification 하는 모델을 추가하여 1차적으로 데이터를 필터링합니다.

사용자가 갤러리로부터 옷 이미지를 선택할 경우, 적절한 옷 이미지 사진을 제시하여 서비스의 성능상 한계를 간접적으로 표현하고, 좋은 결과를 도출하기 위한 사용법을 유도합니다.
결과 사진 Feedback API 구현
저희는 프로젝트 개발을 진행하는 동안, 위에서 기술한 한계점들로 인해 모델 학습이 어렵다는 결론을 내렸습니다.
하지만 서비스의 본질은 사용자의 경험을 고려해야하는 것이기 때문에 “착붙”의 결과에 따른 피드백을 수집하여 추후 모델 성능을 개선하기 위한 데이터셋으로 활용할 수 있는 파이프라인을 구성했습니다.
기존에는 사용자에게 결과 사진이 전달 된 이후 사용자의 디바이스에 이미지를 저장할 수 있는 기능을 제시했습니다. 현재에는 중간단계에 Feedback API를 추가하여 사용자로부터 모델 결과 대한 피드백을 받은 후, 불만족 피드백을 받는다면 스토리지에 입력으로 받은 옷과 사람 이미지를 저장합니다. 이렇게 수집된 데이터는 추후 더 나은 모델 성능, 더 나은 사용자 경험을 만드는데 중요한 역할이 될 것이며, 성능 개선의 가능성을 토대로 마주한 한계점들을 해소하려는 시도로 볼 수 있습니다.
